Is duckdb all you need for storing and querying OTel?
In a previous post about OpenTelemetry, parquet, and data lakehouses, I mentioned difficulties when you want to push lots of metrics, logs, or traces to object storage with an Iceberg catalog like Amazon S3 Tables. A couple people messaged me, shared expletives, and said the same.
Some good news: there has been progress around this in the DuckDB ecosystem with the new DuckLake 1.0 standard, Iceberg extension features, and the Quack Protocol. To explore some of these ideas in action, I updated the DuckDB OpenTelemetry extension to write metrics, logs and traces via the OpenTelemetry Protocol (OTLP/HTTP) directly to duckdb. This makes it easy to store observability data in anything with existing duckdb support: lakehouses, normal and not-normal filesystems, or object storage. Everything runs in a single process: no extra dependencies or orchestration needed.
DuckDB is evolving into very capable data glue, even for streaming data. Below is some discussion of storing ~gigabytes to low terabytes of metrics, logs and traces streamed into a DuckLake using the new extension. Early benchmarks (see below) suggest if you're working with a modest amount of OpenTelemetry data, it's promising.
Streaming observability data into DuckLake and other catalogs
The idea was to do the following with a couple lines of SQL statements typed into duckdb on a mac:
- Accept OpenTelemetry data streamed over HTTP (metrics, logs, traces)
- Write compressed OTel data to object storage (Amazon S3, Cloudflare R2, etc)
- Keep track of what data you write in a metadata catalog (DuckLake, Iceberg, etc)
- Query the data in SQL with duckdb remotely (Quack Protocol)
- Align to open standards/open source/vendor-neutral
The main reason to do all of this is to get reasonable performance when you want to do SQL queries like "show errors last Monday for the checkout service." If not: just throw parquet files in a bucket, which is what the last post partly explored.
For #1-5, all you do is type a couple SQL commands into the duckdb shell to load and configure a handful of extensions. That gets repetitive so I packaged it up in a docker image with duckdb embedded and pre-configured inside:
docker run --rm --name duckdb-otlp \
-p 4318:4318 \
-v "$(pwd):/data" \
ghcr.io/smithclay/duckdb-otlp:latest
POST some OTel data to :4318, it gets added to local DuckLake, then you can query it with SQL (SELECT * FROM otel_logs).
The trouble is what happens when you have hundreds of thousands of log lines arriving, which without optimizations means many small files being written to object storage. It kills query performance and costs more due to the intricacies of cloud object storage billing:
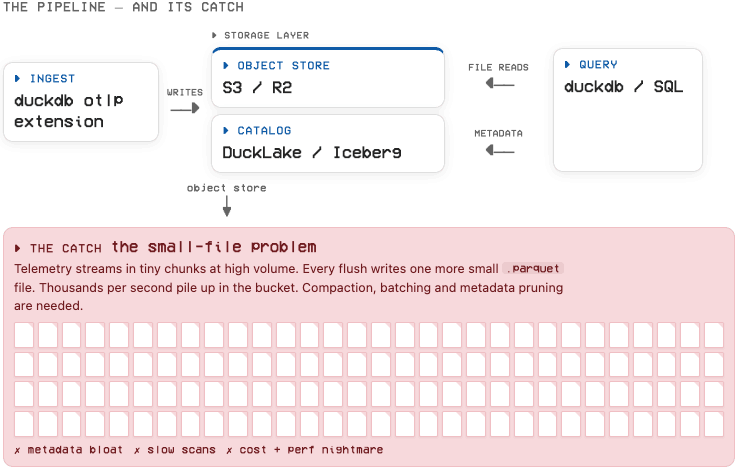
Every telemetry pipeline that writes to object storage has ways to mitigate this by batching data to reduce the number of writes. This involves a tradeoff that varies widely depending on what you’re doing: how fresh do you need the data to be? You end up with configuration knobs that might dial the bill way down, but fresh data might not be queryable for a while.
DuckLake is building in automatic-ish maintenance features and making it easy to use via a single command that can merge small files together (compaction) or reduce metadata. Iceberg catalogs like S3 Tables or R2 Data Catalog have had variations of this as well. If tuned correctly you might get reasonable query performance and a cheap object storage bill.
Until then, after some basic synthetic log ingest benchmarks and the official duckdb benchmarks: it seems promising. The duckdb-otlp extension was able to write ~100k log rows per second to remote cloud catalogs, which comes out to ~2.5 TB/day of data for a single duckdb process.
| Catalog | Durable rows/s | Accepted MiB/s | Drain Time |
|---|---|---|---|
| Local DuckLake | 97,545 | 29.9 | 0.21s |
| Local DuckLake, R2 Storage | 96,911 | 30.2 | 0.62s |
| Neon DuckLake, R2 Storage | 90,850 | 30.1 | 0.56s |
| S3 Tables Catalog (Iceberg) | 90,390 | 29.5 | 2.82s |
| R2 Data Catalog (Iceberg) | 88,128 | 30.0 | 4.80s |
Yes, more benchmarking is needed. That's a future post.
Grafana goes swimming in a DuckLake
Performance aside, there's a major UX problem: open-source observability tools use their own special-purpose databases and query languages (PromQL, etc)... not SQL. Visualization tools like Grafana can be extended to support SQL via plugins, but it's not out of the box.
There are other people working on this, recently learned about Gigapipe and vibe-weekend-coded a basic prototype here. For simple queries in PromQL/Loki/Tempo, you can get reasonable-looking dashboards in Grafana, powered by SQL queries in a duckdb instance fronted by compatibility APIs:
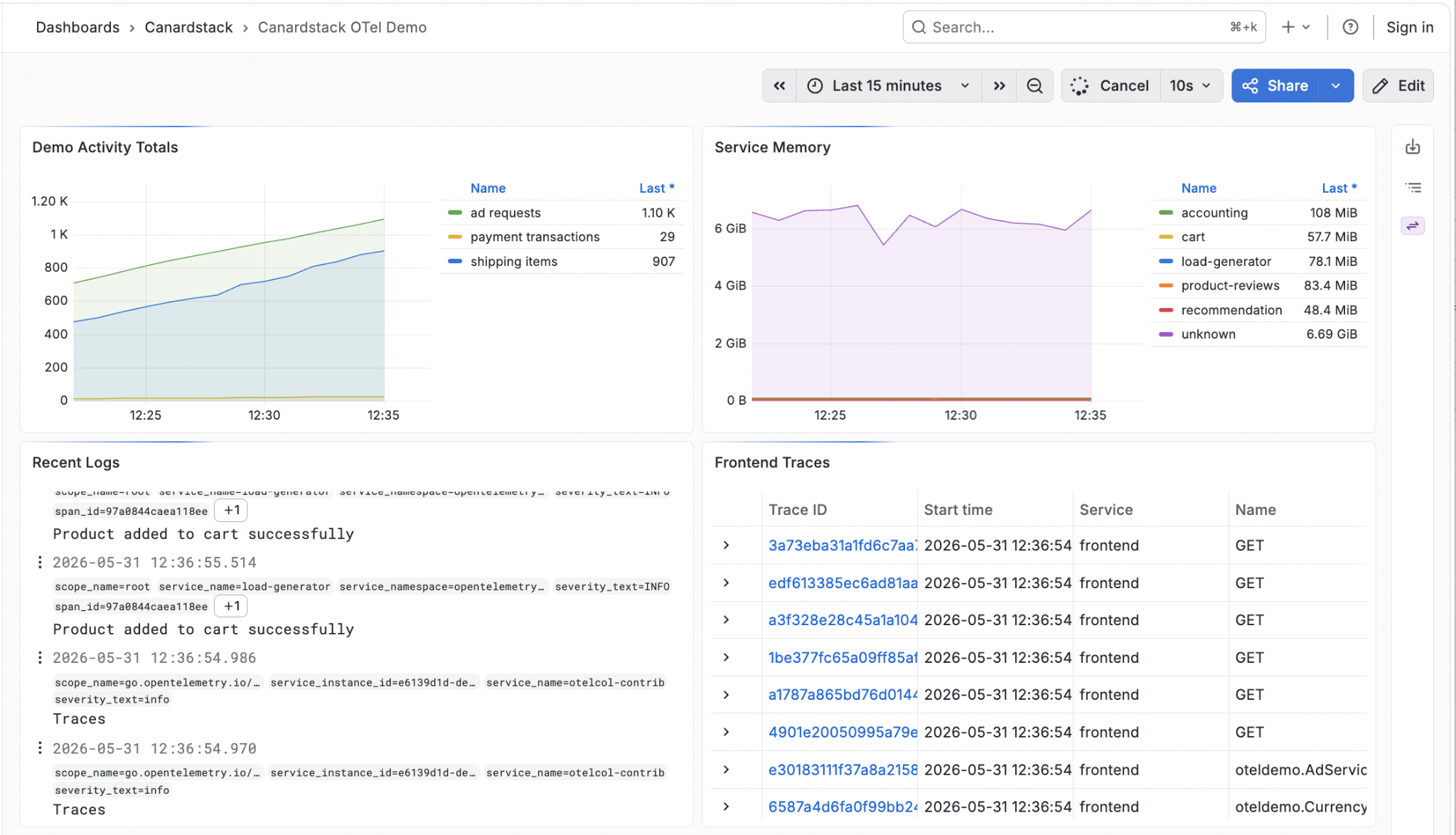
There's also the parallel universe of visualization and analytics tools in the analytics world that work well with duckdb. Perspective is doing really cool things inside of browsers with wasm, for example.
Quack is also opening up new integration pathways. As a standard, it's just an official and fast way for duckdbs to talk to each other over HTTP (credit to extensions like Airport that have been exploring the idea for a while). Currently in the duckdb-otlp extension, it's an easy way to connect to a remote DuckLake and query it:
ATTACH 'quack:localhost:9494' AS otel_writer (TYPE quack);
FROM otel_writer.query(
$$
SELECT * FROM lake.main.otlp_logs
WHERE service_name = 'quack-local-ducklake-demo'
ORDER BY time_unix_nano DESC
LIMIT 5
$$
);
What people start building with Quack and how that changes duckdb architecture will be interesting to watch. For example, there's a new extension that runs Tailscale directly in duckdb, making it easy to transfer data and queries across networks and firewalls. The tip of the iceberg (pun intended).
It's promising but early, more data needed
I think people are excited in the analytics space right now because there seems to be momentum in the direction of a vendor-neutral and cheap way to store and structured data, even if there's a lot of it.
In many ways, if you consider ClickHouse, Quickwit, turbopuffer, or LangChain's new tracing database it technically already exists already minus the vendor-neutral and open standard part. The promise of Iceberg, DuckLake, or Delta Lake getting traction is that almost any major closed-source or open-source analytics tool or AI agent can query and read the data with SQL, even if it doesn't know what an OpenTelemetry trace is.
DuckLake and the new quack protocol have some emerging capabilities that could be compelling for ops teams stuck between running their own complex observability infrastructure (Kafka-esque) and paying huge monthly bills to vendors (canine-esque). More data and better benchmarks to validate that and understand how far you can scale up.
I hope this post gets people excited about working on open-source at the intersection of observability and analytics, which has the vibe right now of "something is happening". If you aggree, say hi on duckdb discord or OpenTelemetry Slack or the other channels.
PRs, feedback and benchmark ideas for duckdb-otlp are welcome.
Thanks for reading about my duck-pilled open-source project.